
Statically generating a blog with Svelte + Sapper
I've been working on rewriting my blog since forever. In fact, here's a video I made back in 2015 introducing codingwithjesse.com and my plans to rebuild my PHP blog using the latest and greatest web technologies. In 2015, this meant I was going to make a REST API with Node.js, and build a React frontend. So that's where I started.
Fast-forward three-and-a-half years, and the site still wasn't done. I hadn't spent that much time on it really, so it just had a REST API and an administration area for writing and editing blog posts. I had done a tiny bit of the public side using React but it was still in rough shape.
That's about the time I fell in love with Svelte and decided I wanted to use Svelte for everything. In July, I started migrating my blog from React to Svelte + Sapper. (I enjoy rewriting React code using Svelte so much, I would do it all day if I could!)
Static Site Generation
Sapper by default comes with a Node.js web server, which serves dynamic server-side rendered markup that gets re-hydrated in the browser. Alternatively, you can choose to use the Sapper "export" feature to generate a static web site that works with any web hosting, no Node.js needed.
My administration area using the REST API is not part of this static website; the admin will only run on my local computer, using a local database. The site does not need user authentication or any kind of session state, and it only changes when I write new posts, so I decided that a static website would be perfect, at least for now.
What was easy & awesome?
My experience with Sapper was mostly positive. Often I was surprised at how easy things were. Here are some of those surprises.
1. Getting started
Getting started with Sapper is really easy. The Sapper sample template already has a blog as its example code, and comes with all the build and testing infrastructure that you'll need to get a Sapper website up and running.
2. Rollup
I really enjoyed working with Rollup, also created by Rich Harris, the creator of Svelte & Sapper. If you don't want to use Rollup, you can also choose to use Webpack or another build tool, if that's what you're into.
3. Static site generation
The static generation worked great! It starts at your homepage and crawls your site like a spider, looking for new links in any <a> tags it can find. This meant that my secret administration area was excluded, which was exactly what I wanted anyway. It creates directories and index.html files, to create all the URLs you've defined.
4. Static websites are fast!
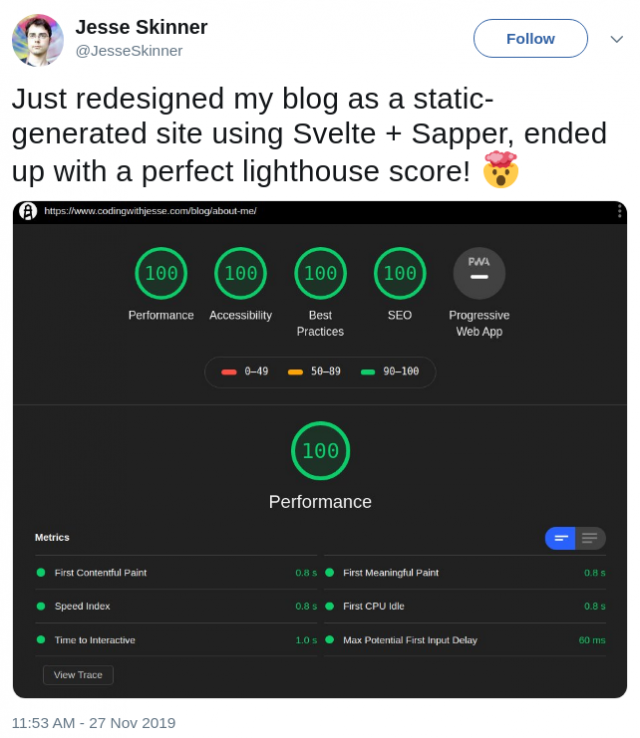
Once the static site was live, it didn't take long to achieve a perfect lighthouse score! I honestly did not think that was possible, but here we are:
5. Routes without a router
The way routes work in Sapper is really easy and powerful. You put Svelte components inside the src/routes/ folder to define new routes. If you want a URL like /blog/my-post, you can make a Svelte component in src/routes/blog/[slug].svelte and use the slug to dynamically look up the blog contents in order to render the page. This syntax for dynamic routes is so awesome that even Next.js was inspired to do the same.
6. Client-side static search
I wasn't sure if I'd be able to keep the search box on my blog, since there would be no database to search. Turns out all I needed to do was have the search page use the /blog/all.json route as a data source. I passed the search terms as a query parameter like /blog/search?terms=example The search page parsed the URL to get the search terms, then filters the blog posts client-side to render the results. Might seem ridiculous to have a single JSON file with all the blog posts in it, but on my blog the all.json is only 142kb which is smaller than some JavaScript frameworks! I might write a blog post going into more detail about this client-side search, if anybody is interested?
7. Deployment
Deploying a static site is easy. I use shared hosting so I wrote a bash script that does the following: 1) npm run export to generate the static site, 2) zip up the static files into a zip file, 3) upload the zip file to my web server with scp, 4) ssh into the server and unzip the zip file into the correct folder, 5) delete the zip file. I don't need a complex CI system, though maybe I'll set that up down the road. For now, running a bash script after each blog post is fine for me.
What was hard & confusing?
Learning any new tool has its ups and down. There were some concepts that I didn't understand correctly, and that led me to make mistakes, causing a few bugs and broken pages. Here are some of the things I learned in the process.
1. JSON API
It took me a while to figure out that all the API calls needed to be "JSON API" calls inside server routes that would later generate .json files. Confused already? Let me walk through an example.
When you're viewing a page of the blog, and you click a link to another article, the Sapper client-side code will fetch the contents for that page asynchronously. It can't access the actual REST API so it needs to get the data from a static file, and the best approach for that is to have static .json files in your static site.
For the src/routes/blog/[slug].svelte component I mentioned above, I created a related src/routes/blog/[slug].json.js file that acted as a "server route" that will cause Sapper to export a /blog/my-post.json file for each post.
For more on this, including code examples, check out the Sapper documentation about Server routes.
2. Every page needs to be discovered with a crawler
As I mentioned above, Sapper uses a web crawler to start at your homepage, and dig through looking for links to pages. This means that any pages you might have needs to be linked from an <a> tag. You cannot have any truly secret pages.
To achieve this, I made a single route /blog/all that acts as a site index, with a link to every blog post, plus some extra links at the bottom just so Sapper will know about them. For example, I needed to include an extra link to my RSS feed and my Newsletter signup that weren't linked to with <a> tags anywhere else.
3. Vendor CSS was awkward
Of course I needed to have beautiful looking code examples on my blog, so I integrated Prism.js. I couldn't figure out how to import the prismjs-monokai.css vendor stylesheet into the Svelte component that needed it, so I ended up just using a <link> tag to load it from the template.html, similar to the global.css example file that comes with the Sapper template.
Seems there is a solution that uses a Rollup plugin to allow you to import stylesheets from the Svelte <script> block but I didn't go down this road (yet). Maybe doing an @import in a Svelte <style> block will be something we can do one day, but not today.
Conclusion
Unlike Svelte v3, which is very much ready for production, Sapper is technically still in early development, and hasn't yet reached version 1.0. Still, it was a joy to use, and for something like a blog I think it's perfect. I'm already using Sapper in two other production web applications, as I feel Sapper is mature enough for my needs.
Further reading
- Sapper documentation is a great place to start
- Svelte & Sapper Discord if you need help
- Static Svelte: JavaScript Blogging with 93% less JavaScript
